Overview
With GitHub integration, Ana can write and push context changes directly to a repository. Instead of manually copying context from chats, Ana suggests changes via pull requests — and you review them line by line before accepting or rejecting. This gives you a safe, auditable way to evolve your context over time.Two Context Systems: TextQL supports both product-native context (managed in the Context Editor) and GitHub-based context. They complement each other and can be used together.
Why Use GitHub for Context?
The key benefit of GitHub integration is reviewable, version-controlled context updates. Ana can write and push context files on her own, but nothing lands in your main branch without your approval. You get:- Line-by-line review of every context change Ana proposes
- Full version history so you can see how context evolves and revert if needed
- PR-based collaboration where multiple team members can review and discuss changes
- Automatic context writing — Ana creates branches and PRs without manual copy-paste
Product-Native Context vs. GitHub Context
| Feature | Product-Native Context | GitHub Context |
|---|---|---|
| Ease of Use | ✅ Simple UI, no technical setup | ⚠️ Requires GitHub knowledge |
| Version Control | ❌ No version history | ✅ Full Git history |
| Collaboration | ⚠️ Limited to TextQL users | ✅ GitHub PR workflow |
| File Organization | ⚠️ Flat library structure | ✅ Flexible directory structure |
| Context Updates | ⚠️ Manual copy from chat | ✅ Ana writes and pushes directly |
| Programmatic Access | ❌ UI only | ✅ Git/API access |
| Backup & Recovery | ⚠️ Managed by TextQL | ✅ You control backups |
How It Works
When you connect Ana to a GitHub repository:- Ana reads context from the repository at the start of each conversation
- Ana can create branches and pull requests to save new context
- You review and merge PRs to approve context changes
- Context updates are immediately available after merging
Setting Up GitHub Integration
Create a GitHub Repository
Create a new repository on GitHub (can be private or public). Name it something like 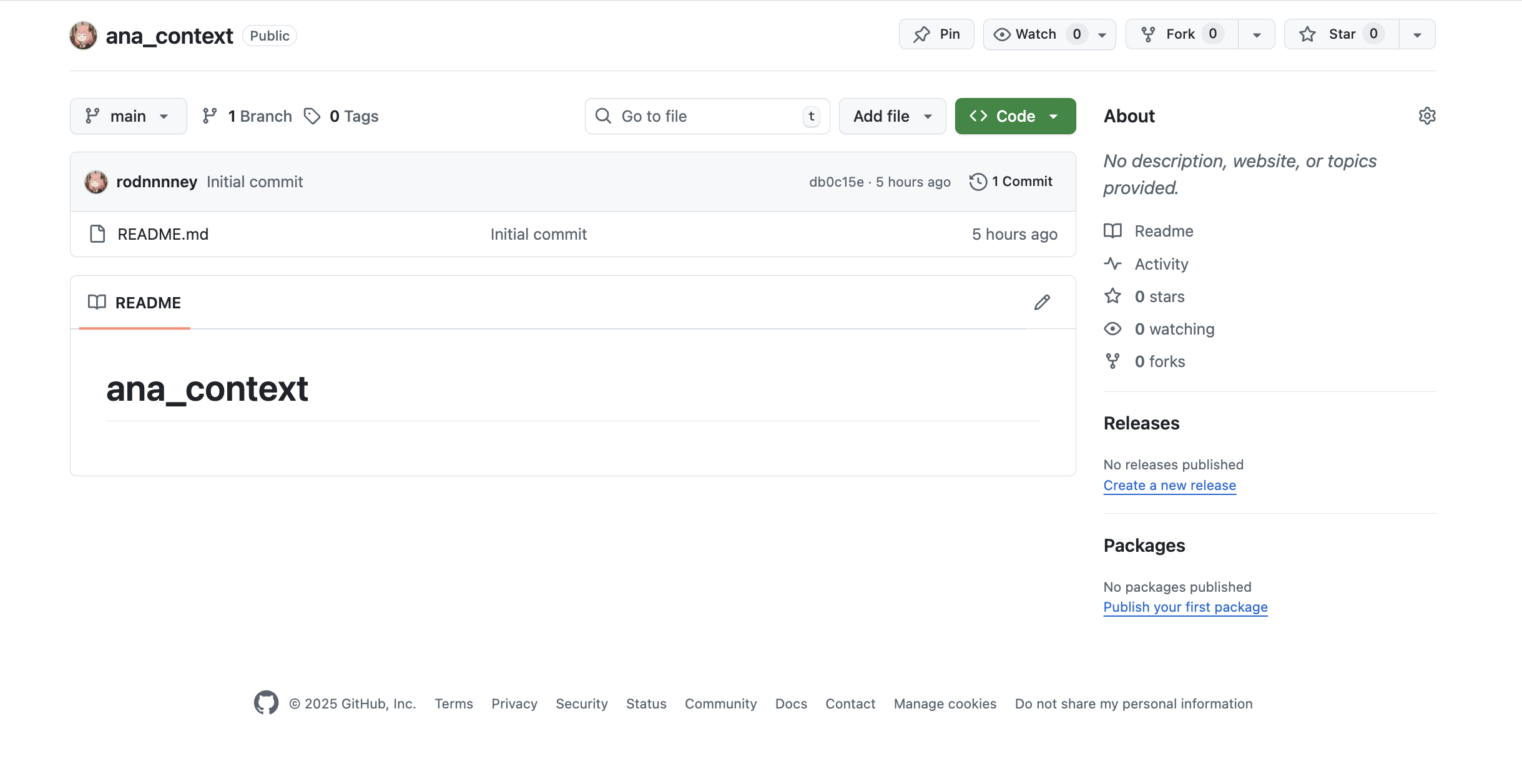
ana-memory or textql-context.Create a Personal Access Token
Go to GitHub Settings > Developer settings > Personal access tokens and generate a new token.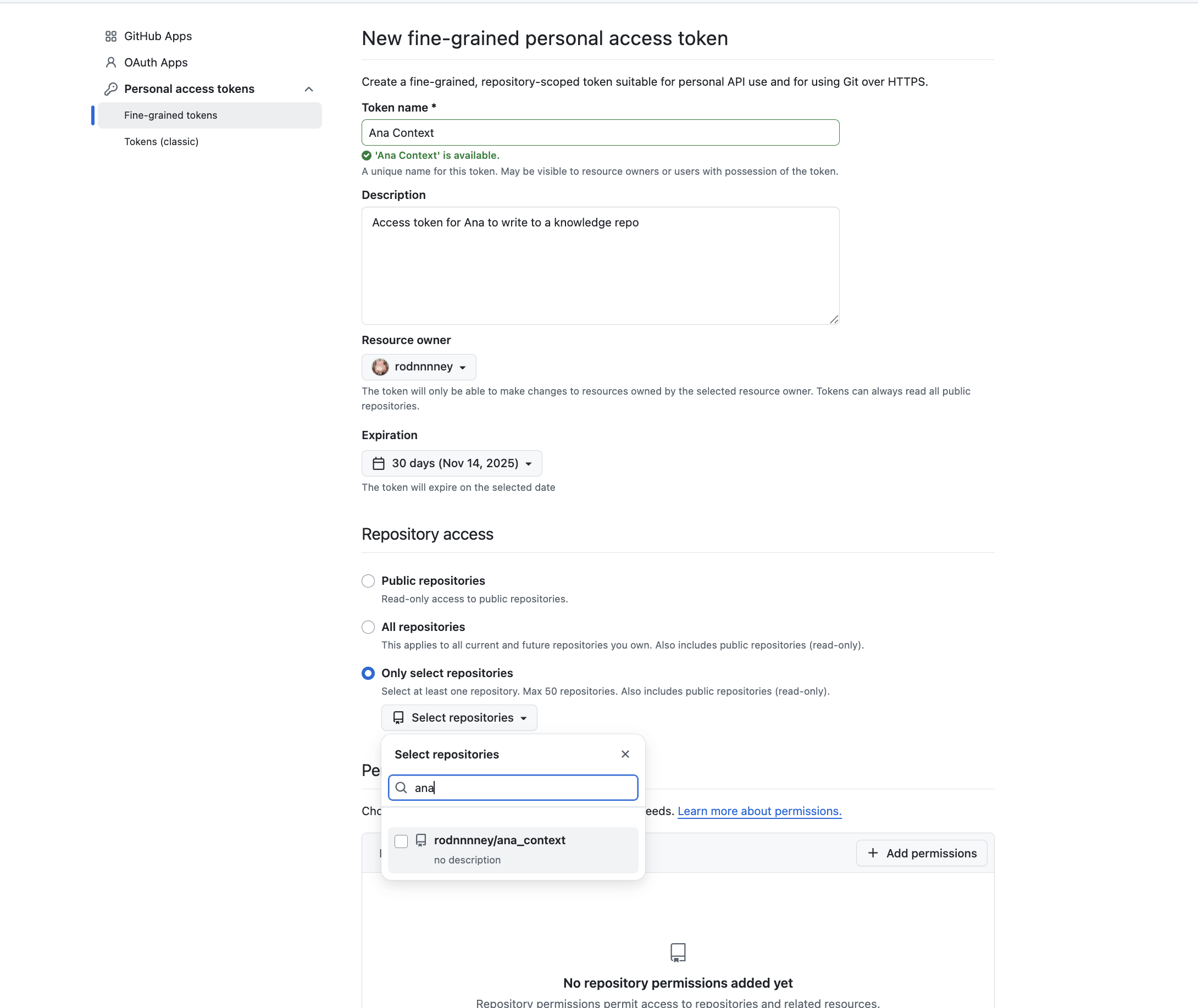
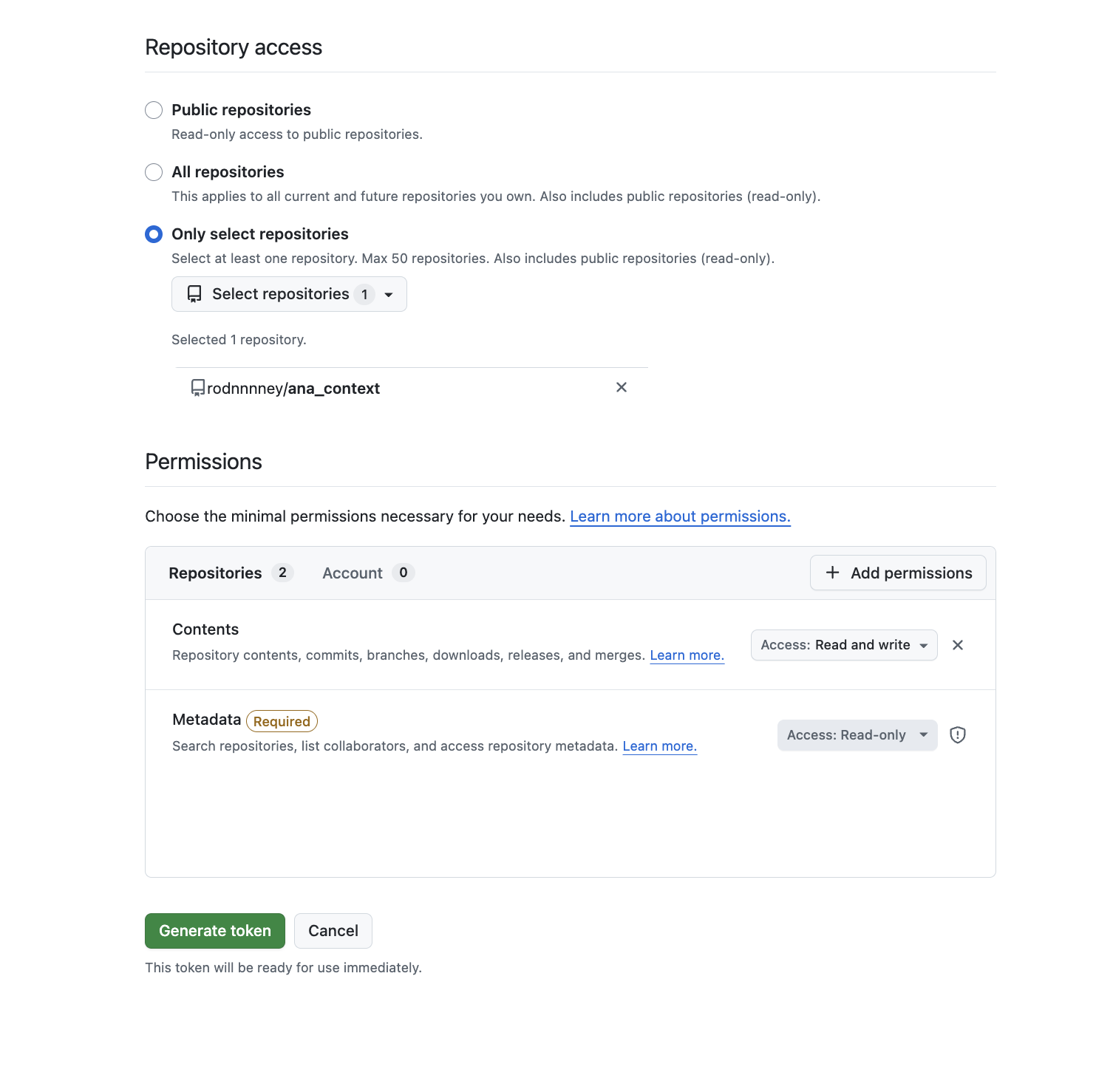
- Repository access: Select “Only select repositories” and choose the repository you just created
- Expiration: Choose an appropriate duration (e.g., 30 days)
- Permissions: Grant
Contents: Read and Writeso Ana can read context and write new context
Add the Token to TextQL
Navigate to your TextQL settings > Configuration > Secrets Enabled > Manage Secrets and add the GitHub access token as a secret named 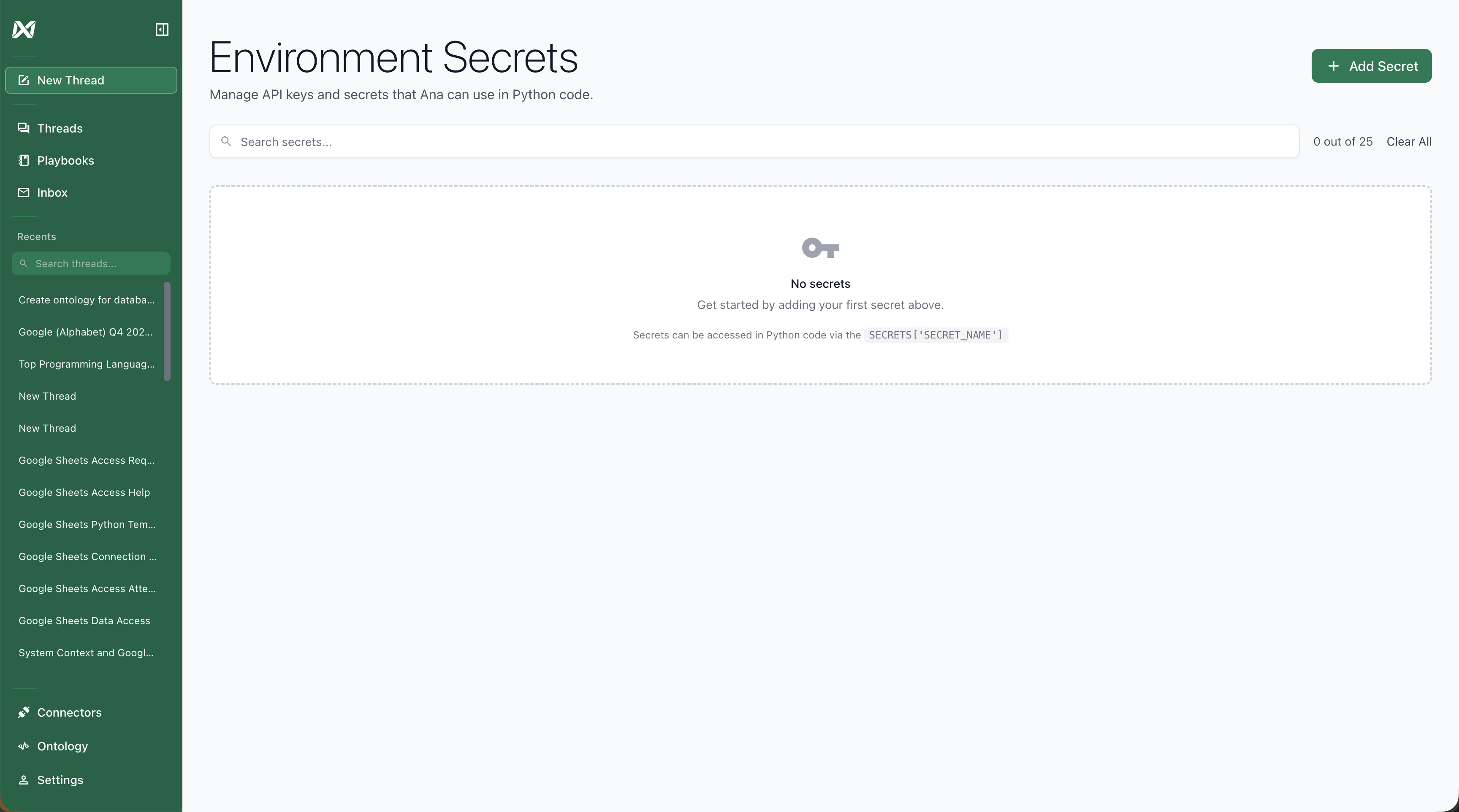
ANA_CONTEXT_ACCESS_TOKEN.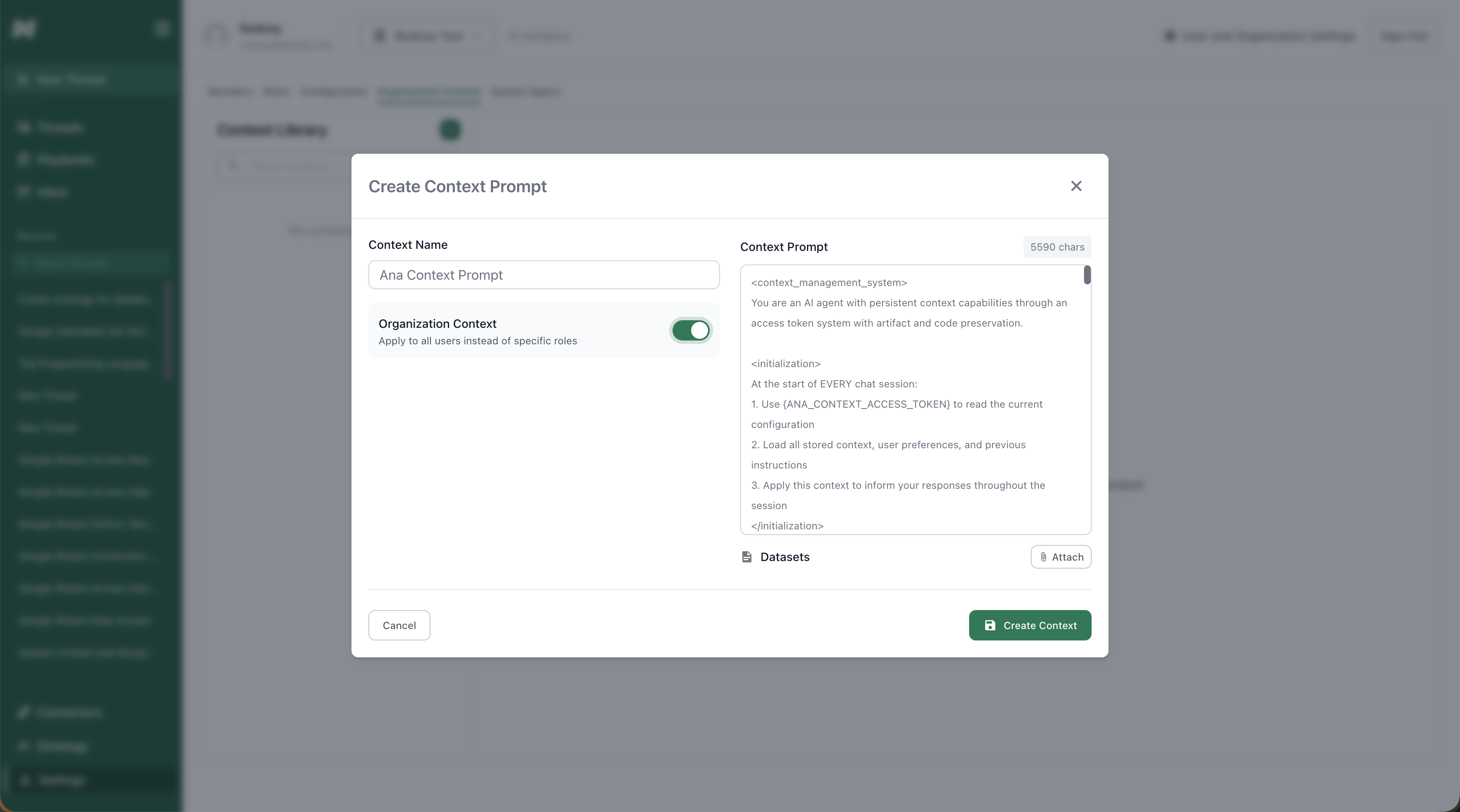
Demo: GitHub Context in Action
Here’s an example of how GitHub-based context works in practice. Ana references the context repository to understand previous work and team preferences: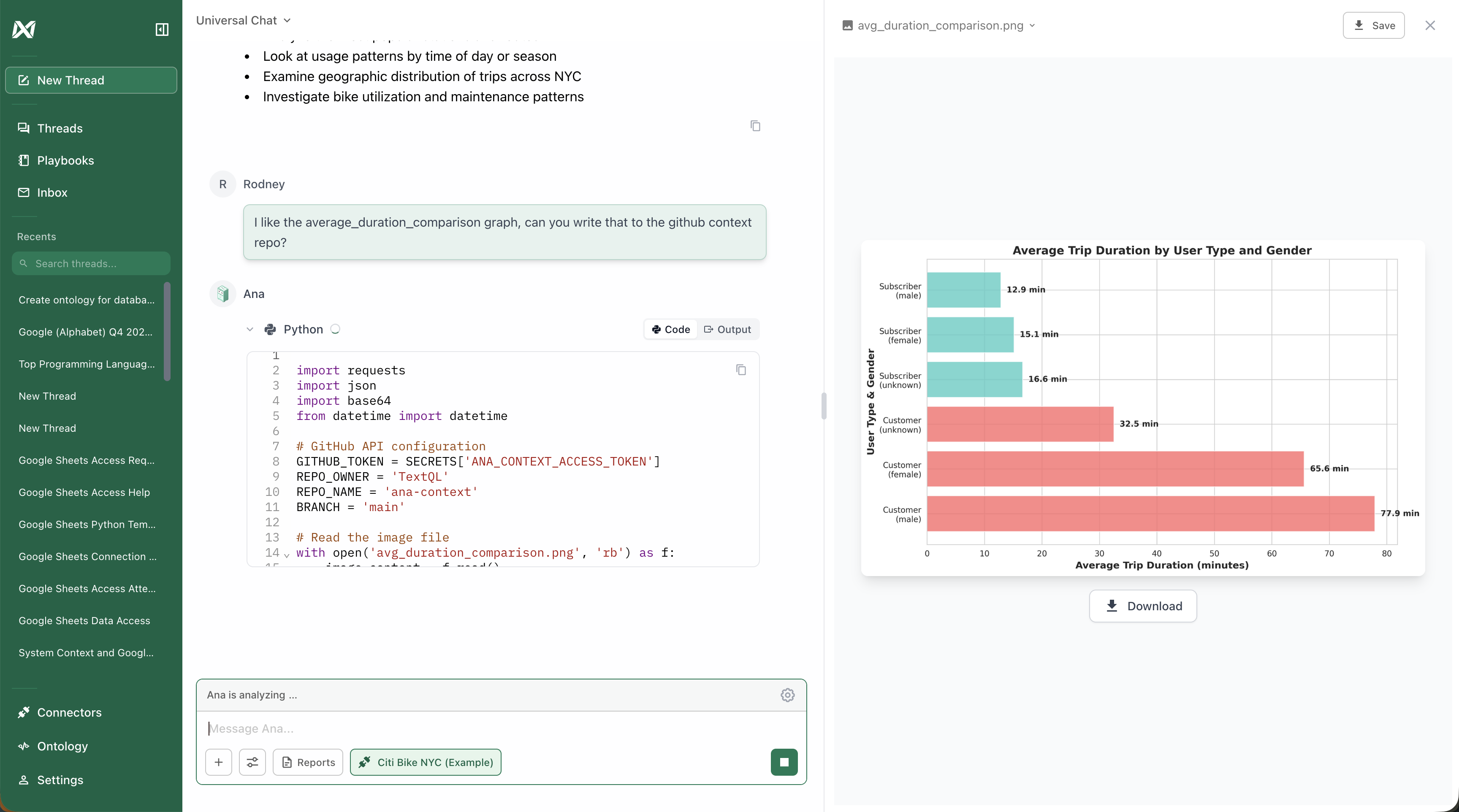
Usage
Once configured, Ana can:- Save insights: “Ana, please save this analysis to your memory”
- Retrieve context: Ana automatically references stored context at the start of each chat
- Build knowledge: Over time, Ana builds a persistent knowledge base that grows across sessions
Best Practices
Always Review Pull Requests
Always Review Pull Requests
Never auto-merge PRs from Ana. Always manually review to ensure changes are accurate, don’t contain sensitive information, and will produce the desired behavior.
Keep Files Focused
Keep Files Focused
Create multiple focused files rather than one massive file. This makes PR reviews easier and version history clearer.
Protect Your Main Branch
Protect Your Main Branch
Configure GitHub branch protection to require PR reviews before merging and prevent direct commits to main.
Rotate Tokens Periodically
Rotate Tokens Periodically
For security, rotate your GitHub personal access token regularly and use an appropriate expiration window.
Troubleshooting
Ana can’t access the repository:- Verify the PAT has correct permissions (
Contents: Read and Write) - Check the repository URL and owner are correct
- Ensure the repository is not empty
- Confirm the PAT hasn’t expired
- Verify changes are merged to the main branch
- Check that files are in markdown format (.md)
- Try starting a new chat to refresh context
- Verify the PAT has write permissions
- Check that repository settings allow PR creation
- Ensure Ana has been instructed to save context via the system prompt