The TextQL Virtual Sandcastle Service is a cloud data platform that consumes resources for distinct functions. The service provides agentic capabilities for data-intensive workloads through Ana, and is available in different service tiers and deployment options. Workloads are processed using virtual compute resources and AI inference, charged based on Agent Compute Units (ACUs).
Compute (Virtual Sandcastle Service).
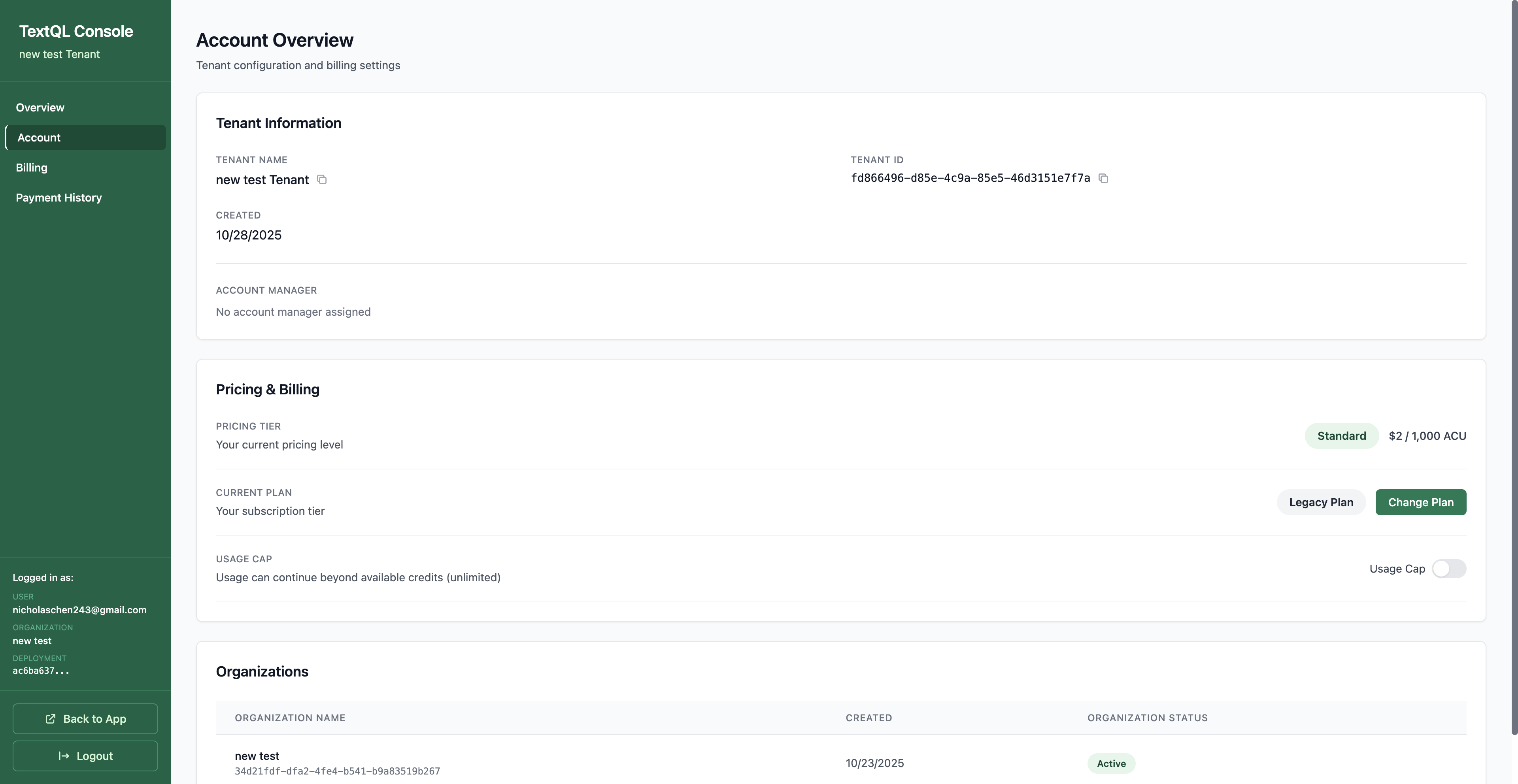
TextQL bills for compute resources using purchasable Agent Compute Units (“ACUs”).
Virtual compute instances consume ACUs at a rate of 500 ACUs per instance-hour.When you start a workload (such as starting a conversation with Ana or running a playbook), a dedicated sandbox is provisioned for your work. This sandbox remains warm and available for 1 hour after your last activity, consuming ACUs continuously during this time. After 1 hour of inactivity, the sandbox is automatically released.Dashboards. Published dashboards run on the same sandbox-backed compute. A dashboard’s sandbox is provisioned the first time it is viewed or refreshed after being released, and that provisioning is the only event that starts a billing period. Once the sandbox is warm, additional viewers, page refreshes, and manual or scheduled data refreshes do not provision new compute and do not incur additional cost. Unlike chat and playbook sandboxes, which release after 1 hour of inactivity, a dashboard’s sandbox stays warm for 24 hours after it was last viewed before it is automatically released — after which the next view or refresh provisions a new sandbox and starts a new billing period. The longer window reflects how dashboards are typically used: viewed repeatedly throughout the day, often by multiple people on a recurring daily cadence, so a 24-hour window keeps a normal day of viewing to a single provisioning instead of re-billing on each visit.AI Inference.
TextQL offers AI inference capabilities powered by industry-leading large language models from Anthropic, OpenAI, Google, and other providers.
Inference charges are based on the number of input and output tokens processed during your interactions with Ana. Input tokens represent the context provided to the model (your questions, relevant data, and conversation history), while output tokens represent Ana’s generated responses.
Token consumption is calculated precisely and converted to ACUs based on the rates in the AI Inference Pricing table below.
Different models offer varying capabilities and price points — from cost-efficient models optimized for simple queries to advanced reasoning models for complex analytical tasks.
Cache features (where available) provide significant cost savings by reusing previously processed context across related queries.
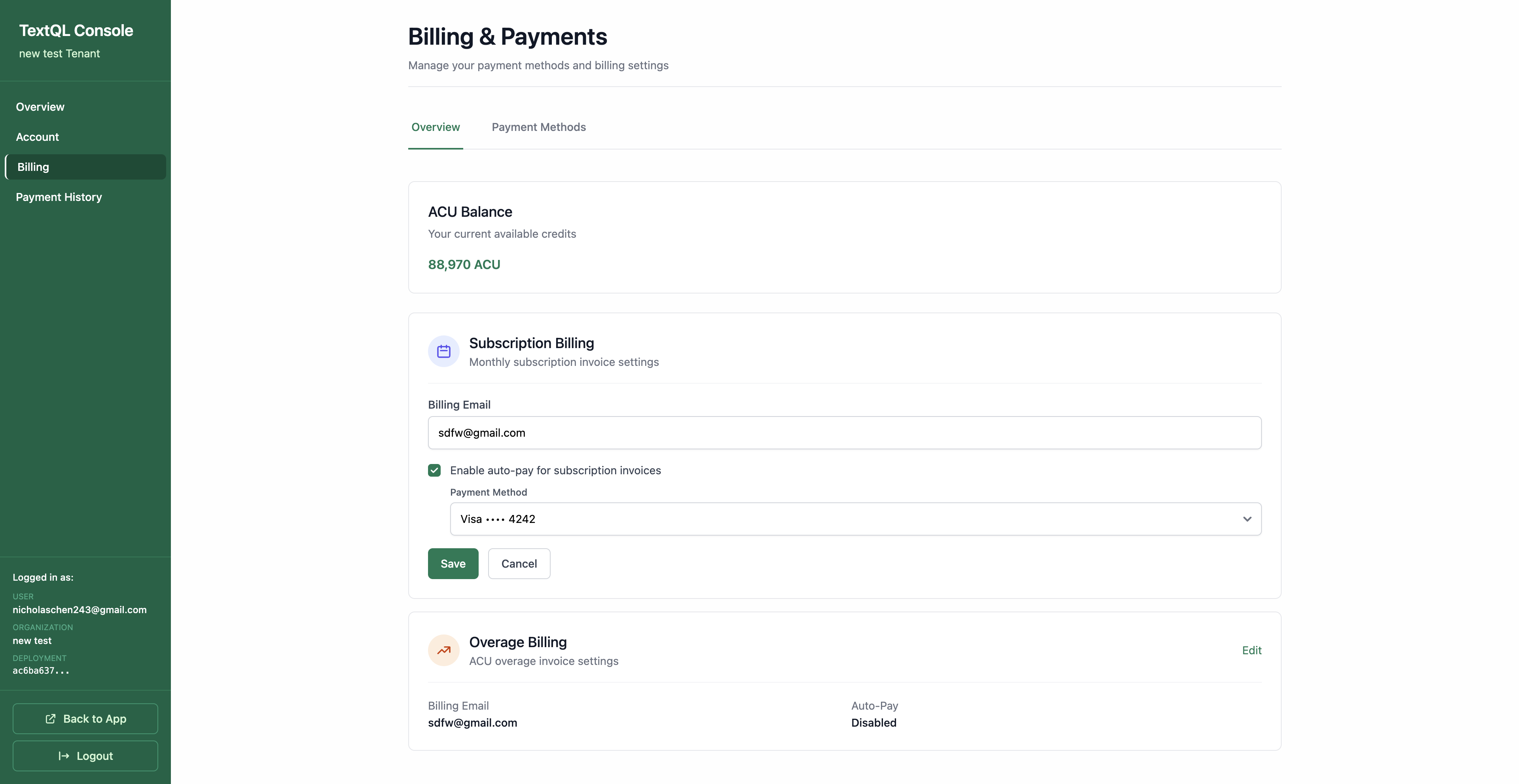
Receive two invoices every month for predictable billing cycles:
Overage Invoice: Any usage beyond your subscription allotment from the previous month
Subscription Invoice: Your upcoming month’s subscription allotment
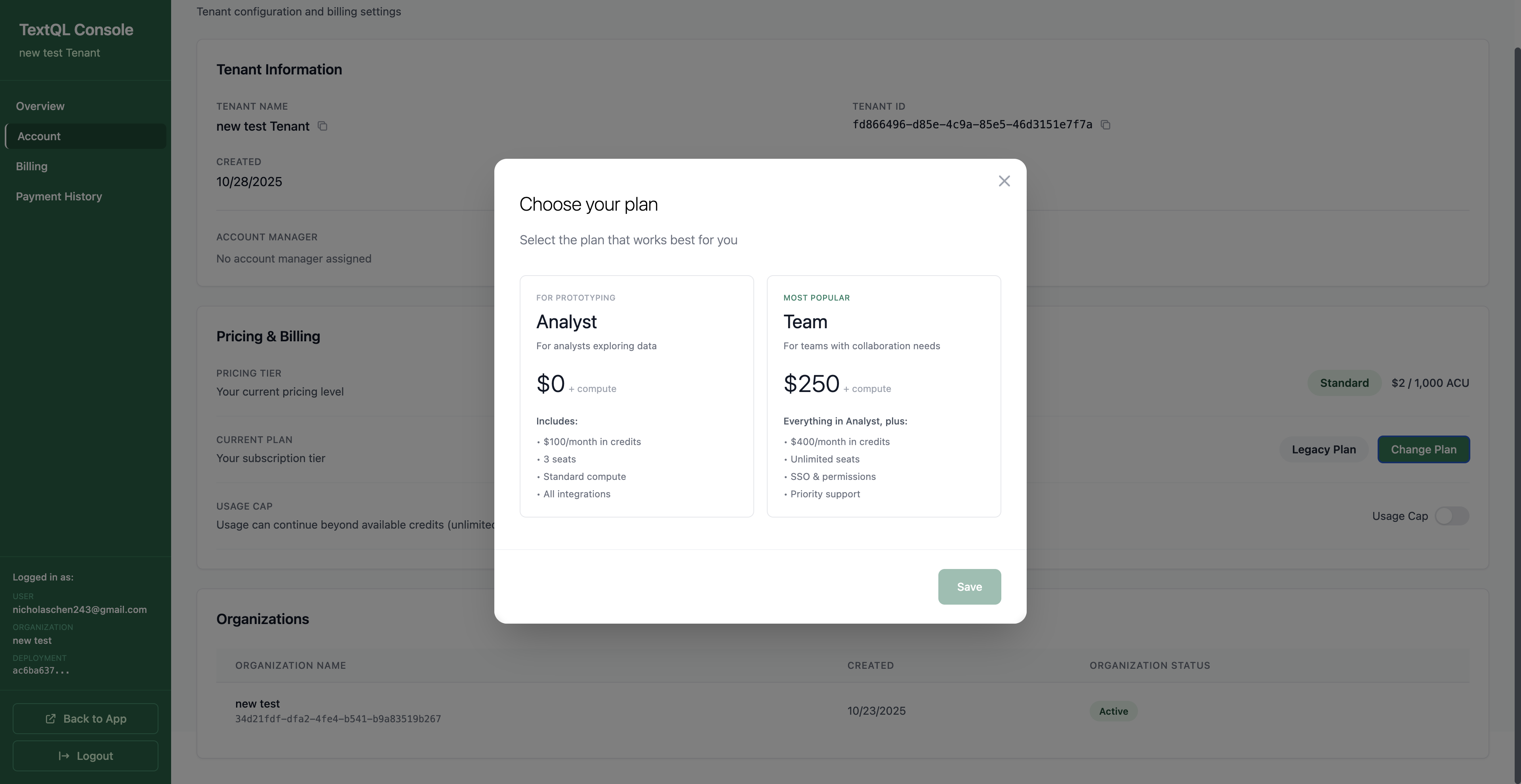
When Auto-Invoice is selected, you’ll see a Change Plan button in your Account Overview under Pricing & Billing. From there, you can view your subscription billing details and overage billing information. See Changing Your Plan for more details, and Payment History & Invoices to view your invoices and receipts.Optional Controls:
Enable Overages: Continue using ACUs beyond your monthly allotment. You’ll be invoiced for any overages at the end of the month.
Enable Auto-Payment: Add a credit card to automatically charge both your subscription and overages, eliminating manual invoice processing
You can enable auto-pay for either subscription or overage billing and add your payment method directly.Best for: Organizations that prefer traditional monthly billing cycles with predictable payment schedules.
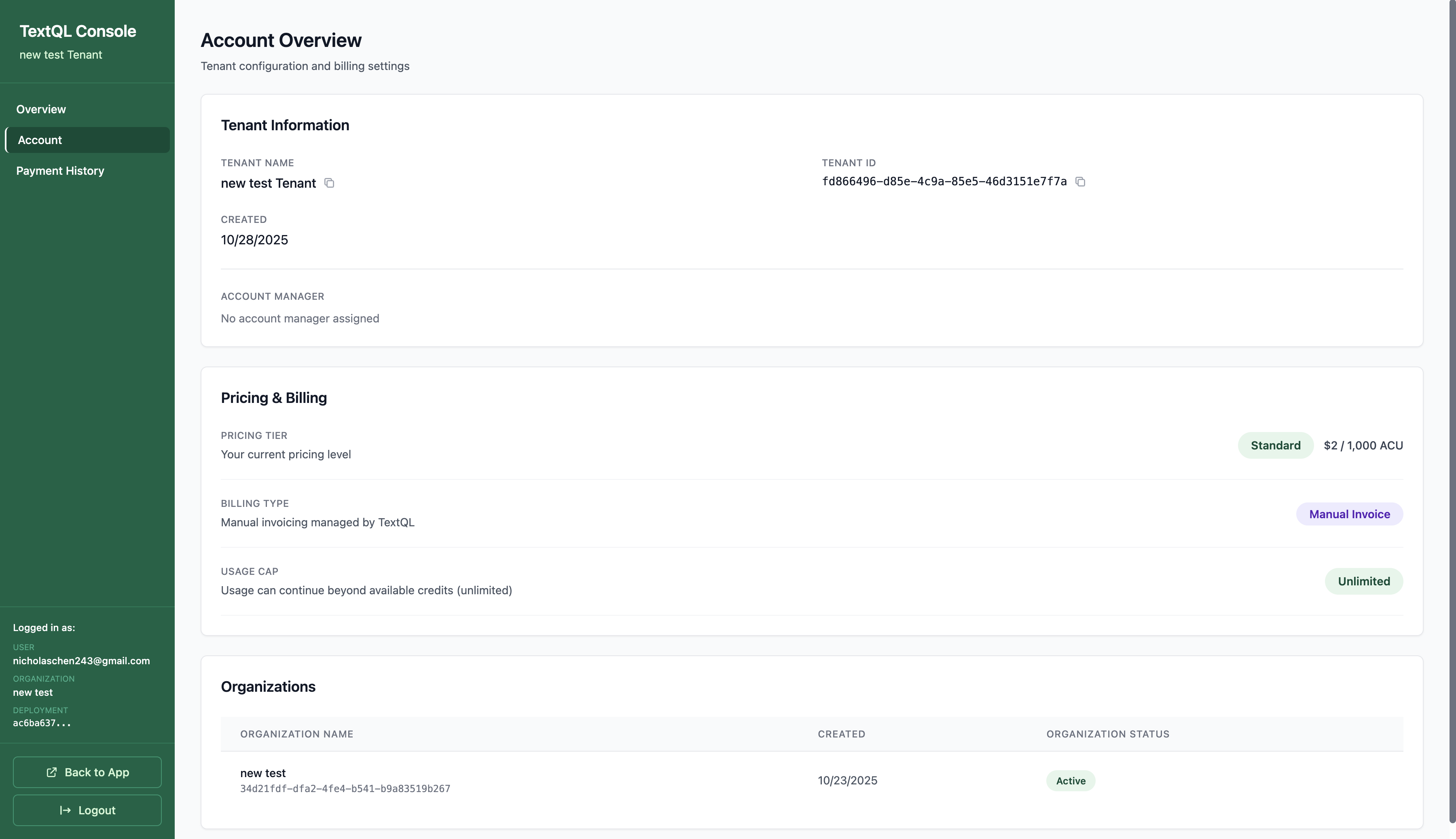
For organizations with dedicated account management, your TextQL account manager handles all invoice details and administration through the platform.
When Managed Invoice is selected, you’ll see Manual Invoice as your billing type in the Account Overview under Pricing & Billing. See Payment History & Invoices to view your invoices and receipts.Features:
Managed Administration: Your account manager inputs invoice details and manages billing
Platform-Delivered Invoices: All invoices are issued through the TextQL platform
Dedicated Support: Direct relationship with your account management team
Self-Service Credit Card Purchases: Optionally add a credit card to purchase ACU credits directly
Automatic Top-Up: Configure automated credit purchases when your balance drops below a threshold
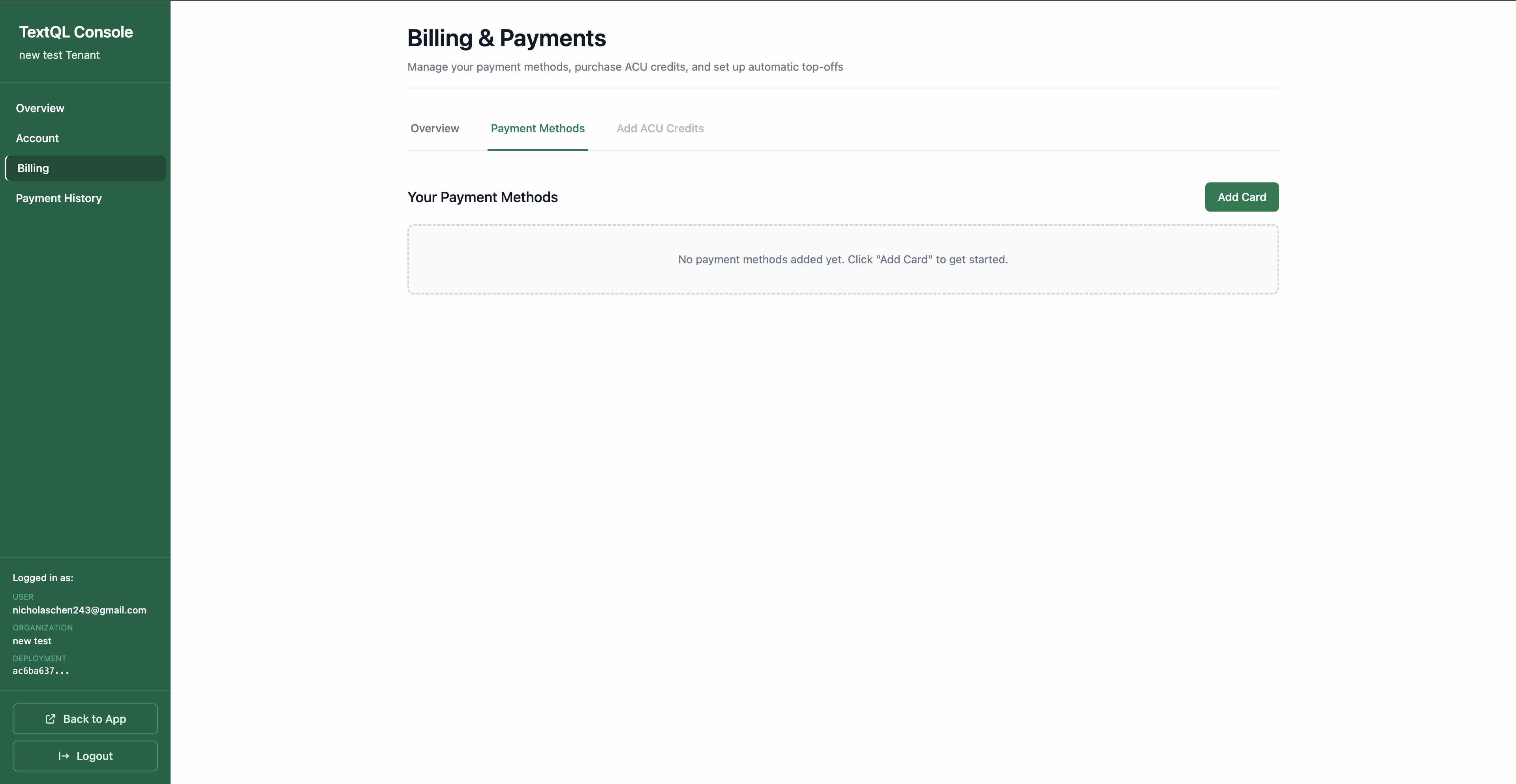
Optional Self-Service Controls:To use self-service features with Managed Invoice, add a credit card first. See Credit Card Payments for step-by-step instructions. Once your card is saved, you can:
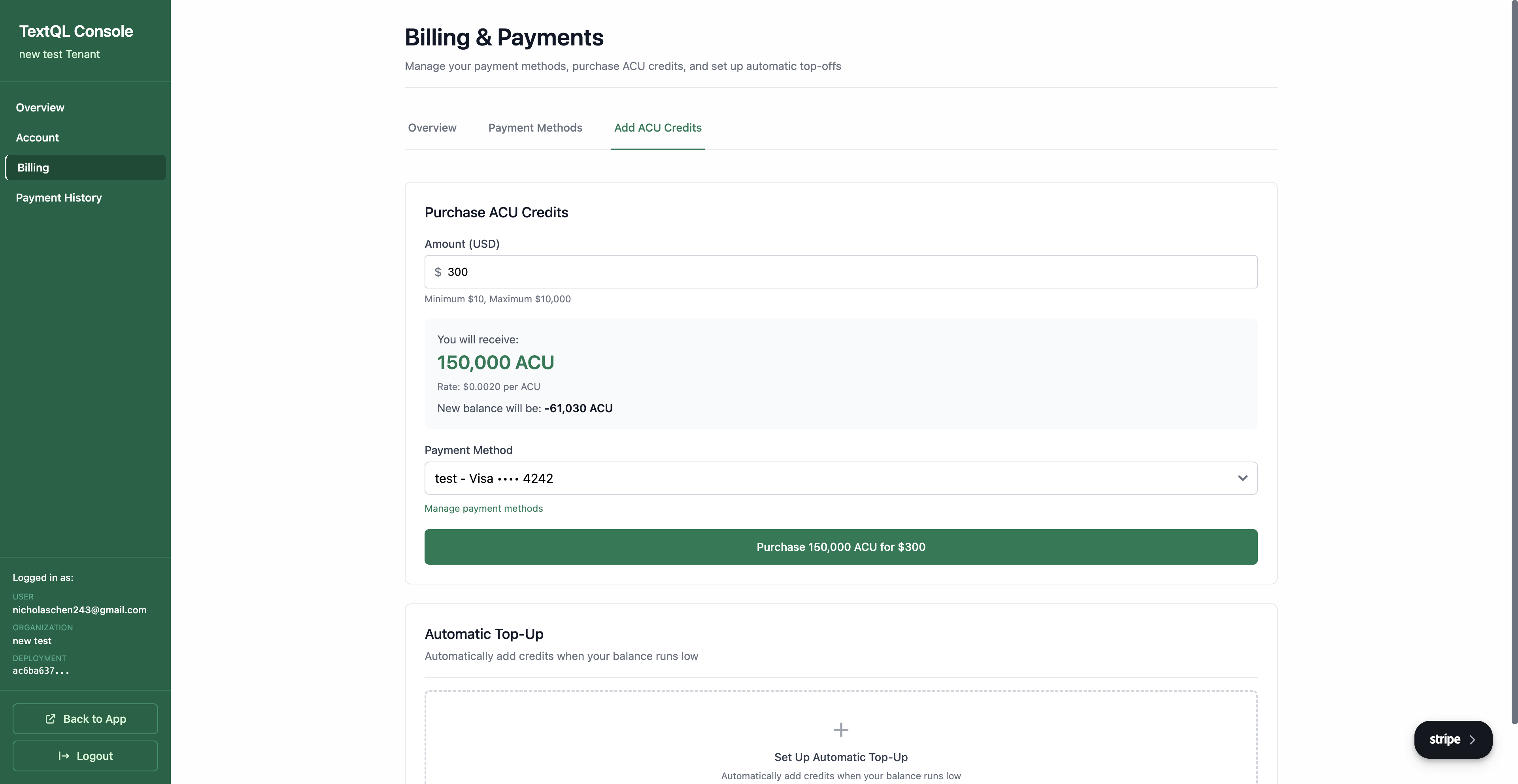
Purchase Credits: Click Billing in the sidebar, then click the Add ACU Credits button to purchase more credits at any time.
Enable Automated Top-Up:
In the Billing & Payments page, click the Add ACU Credits tab
Scroll to Automatic Top-Up and click Set Up Automatic Top-Up
Configure your balance threshold, top-up amount, payment method, and safety limits (max charges per day)
Click Enable Automatic Top-Up
Best for: Enterprise organizations that require hands-on account management and prefer working with a dedicated TextQL representative, with optional self-service credit card purchases.
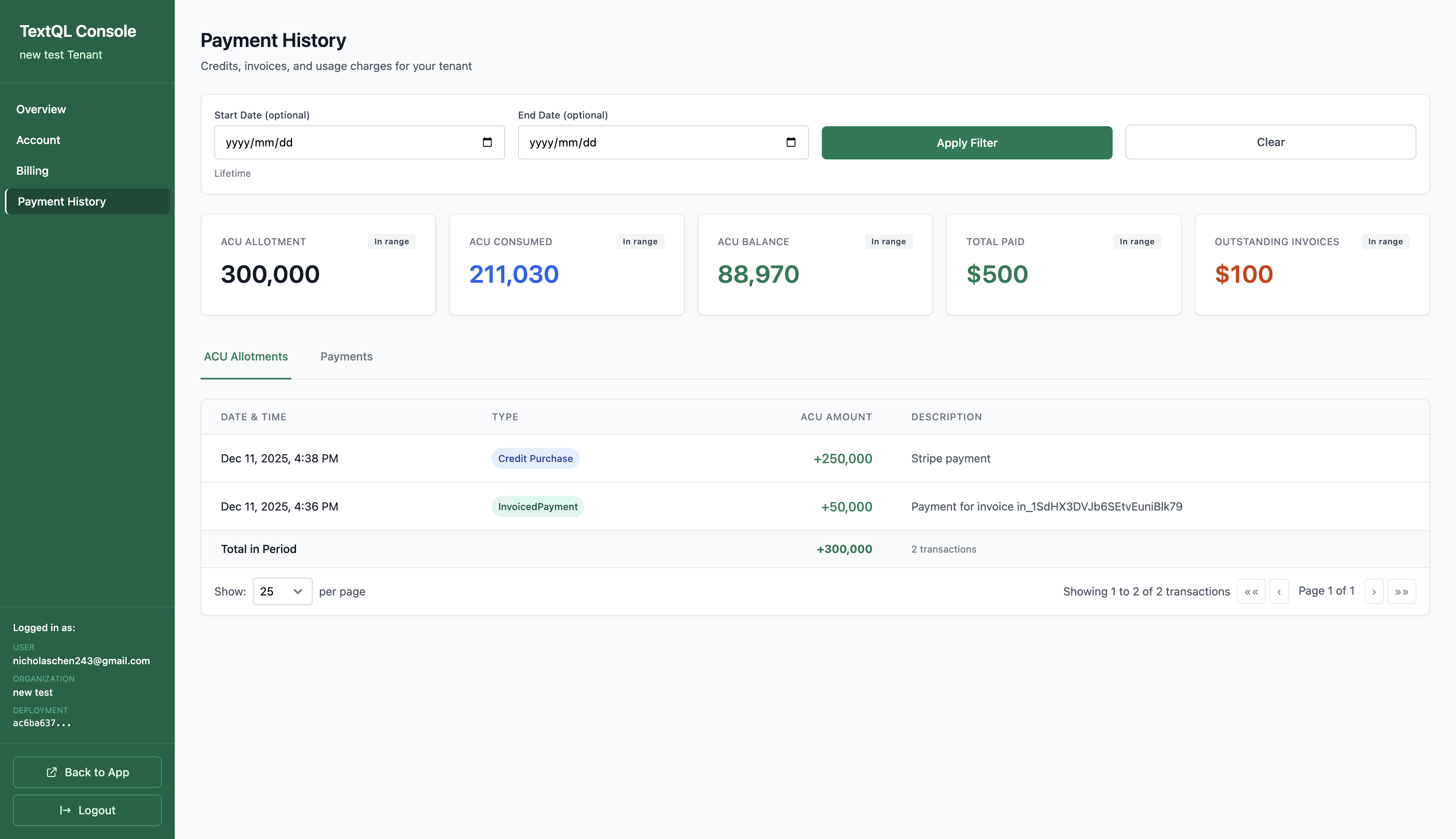
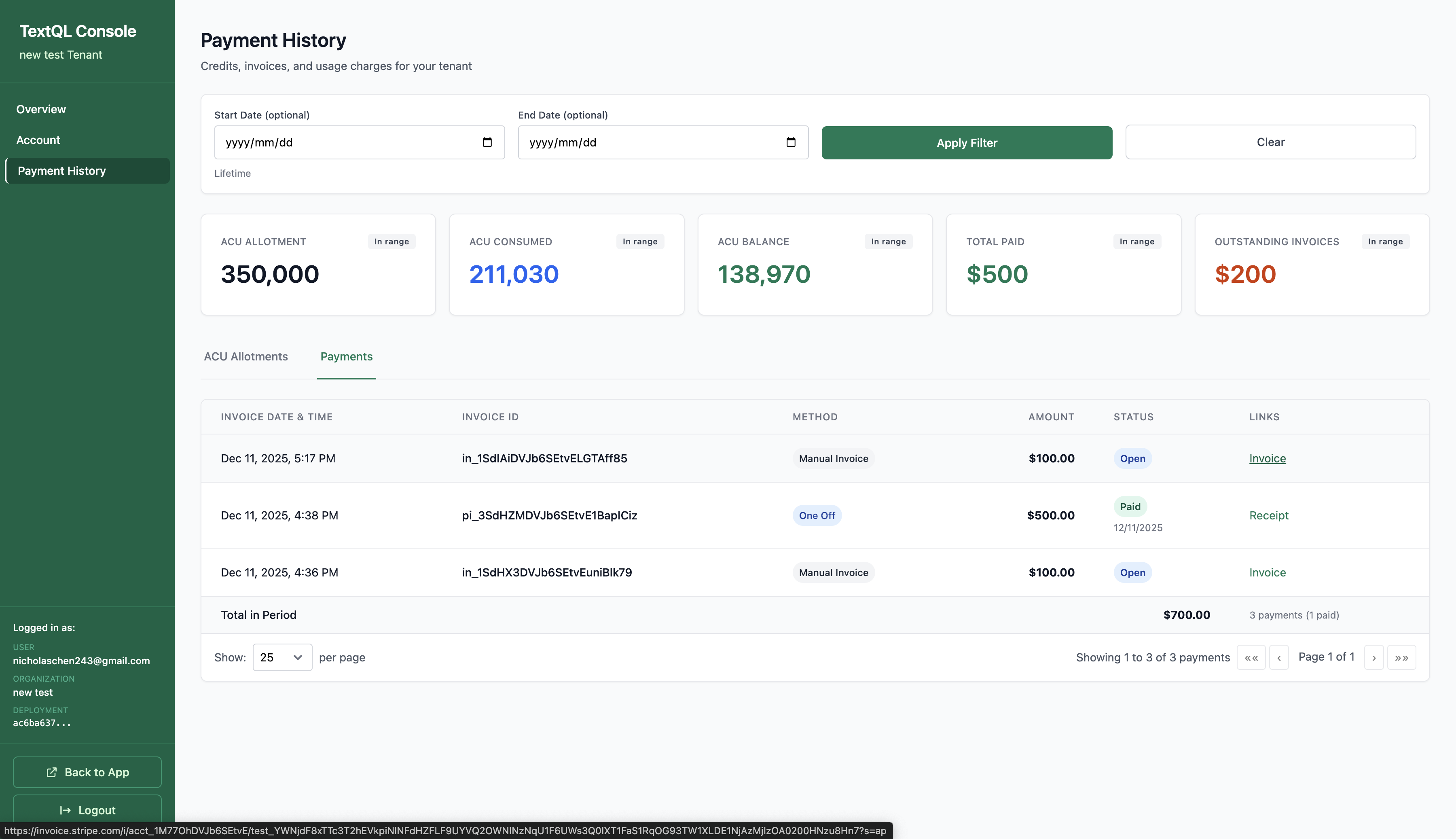
You can view your complete payment history and invoices by clicking Payment History in the sidebar.
Viewing Invoices:Click the Payments tab in Payment History to see your invoices and receipts. Click on Invoice or Receipt links to view the details — you can see the full information and download them for your records.
Stripe Invoices & Receipts:All payments are processed through Stripe. You’ll receive invoices and receipts via email, and can also access them directly from your payment history.
Fast Mode is available for Opus 4.6 and provides significantly faster inference at 6× the standard ACU rates. Fast mode can be enabled per-organization by an administrator.
Ana routes inference requests through a model serving endpoint, which is either provisioned and managed by TextQL or operated externally by your organization. The endpoint configuration available to your deployment depends on your subscription and deployment type.
TextQL-managed endpoints are the default for all deployments. TextQL provisions, operates, and maintains the model serving infrastructure, and ACU consumption is metered at the full token rates listed in the inference tables above.
Customer-managed endpoints are available to non-SaaS deployments (VPC and on-prem configurations) as an alternative configuration. When a customer-managed endpoint is active, inference requests are routed through model serving infrastructure operated by your organization rather than TextQL. Under this configuration, TextQL’s platform role is scoped to session orchestration, credential routing, request lifecycle management, and observability instrumentation — excluding the inference compute layer, which is provisioned and billed independently by you through your model provider.Because the underlying token costs are borne directly by you through your independent provider agreement, and TextQL’s metered cost basis excludes inference compute, network egress to the model provider, and provider-side capacity charges, the platform-operations cost basis applied to customer-managed endpoint requests is 0.25× the token rates listed in the inference tables above.The modified cost basis is applied prior to ACU aggregation and is reflected directly in your usage dashboard and billing statements. It is not listed separately from standard inference consumption.